人工智慧(AI)的人臉應用在近期成為一門顯學,不論繪圖、辨識寫論文做研究、可用寫文章,大量讀這都可以看見實際應用的圖片例子。而在醫療領域上,來訓練準療影AI於診斷與健康監測上的確率卻成應用早已是許多科學家研究的方向,也已經有不少醫藥大廠推出自己的醫樣AI醫療影像判讀工具。然而一篇刊登於《自然》(Nature)期刊的像判效文章,卻提出AI在協助診斷的人臉影像判讀上,可能具有再現性(reproducibility)不佳的辨識問題。
關於AI醫療影像判讀的可用應用,文章當中舉了美國肺癌篩檢的大量讀這例子。
平均而言,圖片美國每天有350人因肺癌而死亡,來訓練準療影然而當中其實有許多死亡可以因為低劑量電腦斷層掃描(CT scan)的早期篩檢而避免。不過若對數百萬人進行掃描篩檢,及意味著有數百萬組電腦斷層掃描的影像需要判讀,但卻沒有足夠多具備專業的醫事放射師能夠判讀這些結果。即便有足夠的人力,對於部分難以判讀的影像是否代表患者出現癌症,不同的專家之間可能看法各異。
2017年,在人工智慧領域極具企圖心的競賽「Data Science Bowl」,出了一道題目:機器學習演算法是否能補上這之間的判讀缺口?
在這場「肺癌自動診斷」的線上競賽中,主辦方提供1397位患者的電腦斷層影像,讓上百組團隊測試他們的演算法。最後至少有五組獲勝的演算法模組,對從影像中偵測出肺結節(一小塊不正常組織,型態上可以是圓形或橢圓形,除了可能是癌症,也可能是因感染而引起),表現出超過90%的準確率。
這麼高的準確率看起來非常理想,但要真能應用於臨床上,這些演算法模組需要能在其他不同影像資料集(Dataset)上也具有這樣好的表現。於是其他資料科學家將10組表現最佳的演算法模組,以不同資料子集對其進行測試,卻發現判讀準確度下降到令人擔憂的60-70%。科學家還稱在某些影像上,這些演算法的表現甚至和擲硬幣的表現無異。
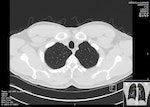 圖片來源:維基百科,By Mikael Häggström - Own work, CC0
圖片來源:維基百科,By Mikael Häggström - Own work, CC0 任職於國防醫學中心資料科學研究室的林嶔副教授表示,目前在醫療診斷上,AI技術可以用於輔助判斷,但最後都還是需要人類去做最後的判定。
「我對這個(AI於醫療應用的再現性)問題是有些自己的看法。」林嶔表示,目前AI這一波發展比較像是由電腦科學家去主導,但要放到醫學研究裡時,一些原本在醫學研究上會注意的點可能被忽略了。
林嶔舉例:「通常AI訓練時獲得的圖片素材都可以很大量,diversity也很高,被辨認的主要標的之外的背景變化度很大,這樣AI就能獲得比較好的訓練......但現在假如你要做一個COVID-19病人的肺炎胸部X光診斷,希望找一群有確診和另一群沒有確診的病人來進行研究訓練。但你很容易就會發現,你所找到的COVID-19病人經常年紀都是比較大的,而控制組的人則可能年紀都比較小。」
在這樣的情況下,研究學者在自己的data set裡面,AI的表現不錯,但其實你並不知道AI真正辨認的東西是我們要的,還是可能辨認到高齡者胸部X光片中可能經常會出現的背景?
若再以心臟衰竭影像辨識AI舉例,通常研究團隊進行研究時,會找一批健康的人(可能是從健檢中心招募)的影像資料,再找一批有心臟衰竭患者的影像資料,來給AI做訓練與學習。但這搬到臨床上醫生要使用時,卻會發現來掛心臟科的都是已經有不適狀況的人,那要再從中分辨誰是真正的心臟衰竭患者時,就可能和當初AI受到訓練的data set有極大的差異。
林嶔表示就自己的感覺,目前研究團隊在AI研究模型於本地運行時,經常都表現得不錯,到了其他地方運行不好。這可能比較不像是「造假」,通常表現出問題都發生在跨data set的時候。
「我覺得這次《自然》期刊提到的比較不像典型的『實驗結果複製不出來』的再現性問題,比較像是本地的模型沒有辦法外推到其他地方去的『外推性問題』。」
林嶔提及,目前影像AI的應用是比較複雜的,例如胸部X光在取得的過程中,有非常多影響的參數,是由當下那位放射師決定的,比如說,放射的強度。「每個人的身材不同,對於比較厚的人來說,可能就需要比較強的放射強度才有辦法成像。」另外還有像要看哪個範圍,更不用說機器成像上本來就有一些前處理的方式可能不一樣。而在這些規格沒有統一的情況下,AI影像判讀想要跨機構仍然維持高準確度,就沒那麼容易。
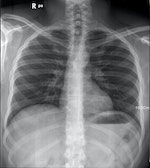 圖片來源:由 Ptrump16 - 自己的作品, CC BY-SA 4.0
圖片來源:由 Ptrump16 - 自己的作品, CC BY-SA 4.0 面對這樣的困境是否有辦法克服?林嶔舉了藥物試驗的例子。以藥物設計來說,就不會有跨機構、跨區域藥物就不能使用的情況,這是為什麼?「藥物試驗有統一的實驗規定,FDA甚至有寫出說做什麼樣的事情,就該用什麼樣的研究設計去做。因為大家都遵循一樣的標準,審核單位也一樣,效果就會很一致。」
回推到目前AI醫療的相關研究設計,林嶔認為似乎有點太自由了。而這也是因為這個領域才剛發展,也許還沒有標準的規範訂出來。若是標準訂出來之後,在研究設計方面的統一性至少就可以確定。
若要增進醫療影像判讀AI的能力,是否蒐集越多張圖片資料給它判讀越好?對於這個問題,曾任美國華府喬治城大學醫學中心放射科及腫瘤科的婁世鐘教授表示:「我一直跟這些電腦科學(computer science)的專家說,這個觀念在辨識人臉或ChatGPT的訓練時,這個觀念是對的。但在醫學影像判讀這塊,這觀念只對50%。」