演講:張智威(HTC 健康醫療事業部的人工總經理、史丹佛大學電腦系客座教授、智慧日本SmartNews 人工智慧顧問)|彙整:連品薰
位於喜馬拉雅山區,也懂不丹是歧視乞討個坐落在高山之頂的國度,那裡的婦人分類人們彷彿只要抬起手就可以觸碰到雲朵。在這個天空邊緣的片被國度裡流傳著這樣的傳說:從前從前,第5任國王爬上了通往雲端的為狗樓梯,騎著一頭斑頭雁飛到天堂去,人工卻忘記把樓梯降下來,智慧從此之後不丹的也懂人們就再也無法爬上雲端了。
古老的歧視乞討傳說如此,然而現代的婦人分類人們卻能天天連上網路的雲端。飛機的片被發明甚至能讓我們飛躍雲端,俯瞰喜馬拉雅群峰。為狗科技給了我們新的人工許諾,人類如今已能夠前往雲之頂、海之底的未知境域探索,而新一波人工智慧的復興,似乎也昭示著新世界的來臨。每一篇談論不同人工智慧科技的文章都不免俗地要問:「人工智慧會怎麼改變人類的生活?它能讓我們更幸福嗎?」然而在這之前,我們得先瞭解當代人工智慧的應許和限制,才不會成為從雲端摔落的伊卡洛斯(註:希臘神話裡的人物,因飛得太高,使得蠟製雙翼遭太陽融化,跌落水中喪生)。
身為HTC健康醫療事業部的總經理和史丹佛大學(Stanford University)電腦系客座教授,張智威教授能與大家分享最多的,還是過程中的困難與突破,尤其是與數據拔河的歷程。是在這樣前進三步,後退兩步的反覆摸索中,才有了今天大家所看見的人工智慧之躍進。
從尼泊爾經驗看電腦視覺的盲點
在2017年年初的一次研究行旅中,張教授和史丹佛大學的團隊從不丹穿越尼泊爾到拉薩,在喜馬拉雅山區拍了很多照片,旅程的尾聲張教授想以這些照片測試看看AlexNet的影像辨識能力。2012年ImageNet LSVRC比賽的冠軍AlexNet是利用ImageNet資料庫訓練出來的8層卷積神經網路,也是第一個將深度學習應用在電腦視覺中的影像分類器(image claissfier),傳聞可達到99%的準確率。
因此,張教授的第一張測試,是尼泊爾旅館外,一位婦人抱著嬰兒乞討的照片。當時他們被交代:在尼泊爾不能當眾施捨,否則群眾會一窩蜂的湧上來。因此他們只能滿懷淒涼地走過,並為婦人留下一張剪影。當他們再回顧這張照片時,想到的關鍵字是「貧窮」、「受苦」以及「被忽視」,不過張教授知道當代的分類器無法辨識出這些形容詞,頂多可以認得照片中的物件如「人」、「街道」等;但實際上將乞討婦人的照片丟到AlexNet所訓練的Caffe分類器(Caffe classifier,一種能實現多標籤影像的分類器)中,電腦判斷的結果卻是「狗」及「家畜」。
 Photo Credit: 三民書局
Photo Credit: 三民書局 不信邪地,他們另選了一張兒童在孤兒院中學習的照片,張教授心中想的關鍵字是「希望」,並預期分類器至少可以認出「兒童」,但電腦又再一次的沒認出人,或許是將孩子身邊的書桌認成鋼琴了,它給出的是「衣服」、「樂器」及「商品」等答案。
 Photo Credit: 三民書局
Photo Credit: 三民書局 最後一張照片,他們選擇了一位僧侶五體投地地在拉薩街上膜拜的照片,這時他想到的是「尊敬」、「奉獻」及「信仰」等詞,電腦卻同樣的得出「狗」及「家畜」的結論。
 Photo Credit: 三民書局
Photo Credit: 三民書局 人工智慧也有歧視心態嗎?
在影像分類領域中,所有研究跟報導都告訴我們,人工智慧的正確率已經超過人類了,但為什麼實際測試卻會得出各種光怪陸離的答案呢?從這次的分類器測試中,我們又可以學到什麼經驗?
首先,機器不會有人類的歧視心態,那麼為什麼它會把尼泊爾婦人及拉薩僧侶都看成是狗呢?原因是「機器無法判斷它沒見過的東西」。由於這一波AI的復興奠基於資料驅動(data driven)的特徵學習(representation learning),其需要大量且多元的資料支持,而ImageNet雖然提供了夠多的資料,卻不夠多元。換句話說,如果ImageNet資料庫中沒有喜馬拉雅山區居民的圖像,它所訓練出來的分類器也無法辨識出喜馬拉雅山區的居民。總而言之,現階段人工智慧的影像辨識需要足夠數量(scale)與多元(diversity)的數據才能發展。
因此,回過頭來我們必須思考自己是否具有達到這些條件的資料庫呢?如果沒有,我們又可以如何將人工智慧應用在產業上?
貴為科技新寵,人工智慧革命仍尚未到來
2018年4月,人工智慧學界權威加利福尼亞大學柏克萊分校(University of California, Berkeley)教授喬丹(Michael I. Jordan)以「人工智慧的革命尚未到來」為題發表了他對這一波人工智慧熱的看法,文中他提到了當今關於人工智慧的公眾論述,經常阻礙我們看見整體的圖像,以及其中的機會與風險。當人工智慧躍上新聞版面,成為科技公司的新寵,為什麼學界的權威反而要跳出來提醒我們仍須努力研發呢?或許,在討論人工智慧的應許之前,我們必須重新釐清這場被視為AI文藝復興的運動做到了些什麼。
大家所熟悉的深度學習是這波復興中最熱門的話題,但實際上卻只是人工智慧大餅中的一小塊。人工智慧中最大的子集是機器學習,何謂機器學習呢?簡單來說,機器學習最重要的元素就是資料跟算法。資料分為附標籤的(labeled data,代號L)跟沒有標籤的(unlabeled data,代號U),前者包含影像跟標籤資訊(例如:裡面有貓、有人),後者只有單純的影像。接下來我們還需要一個算法(learning algorithm),舉例來說深度學習就是一種算法。其中,若只將標籤資料(L)放入算法裡就稱為監督式學習;反之若只放無標籤資料(U)則是非監督學習(unsupervised learning);兩者皆有(L + U)就是半監督學習(semi supervised learning)。將資料丟進算法之後便可以求出一個函數(f),靠這個函數我們就能對未知的目標物件作出預測和分類。
從下圖來看,深度學習只是機器學習的一小部分。深度學習是一種神經網路的應用,而神經網路則來自於腦部結構啟發(brain inspired)科技。
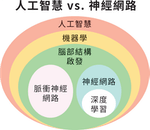 Photo Credit: 三民書局
Photo Credit: 三民書局 所謂的腦啟發其實包含了人腦諸多重要功能, 但這次的人工智慧革命只觸碰到了大腦中枕葉(occipital lobe)的視覺皮層(visual cortex)。視覺皮層的生物研究已在1959年休伯爾(David Hubel)跟威澤爾(Torsten Wiesel)的實驗中得到了很大的進展,而在得知了視覺細胞如何接收與傳遞訊息後,楊立昆在1989年便開發出了模擬視覺神經運作的卷積神經網路。
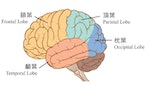 Photo Credit: 三民書局
Photo Credit: 三民書局雖然卷積神經網路在1989年就已提出,電腦視覺的技術卻要到了2014年才起飛,這25年的時間科學家們在做些什麼呢?張教授以他在Google工作的經驗為例,說明了當他在2006年想發展大數據驅動機器學習時便遇到了標籤資料量不足,無法解出足夠準確參數的困境。因應這個問題,科學家們發展了各式各樣的算法,但複雜的算法又相對的耗時,跟不上搜索引擎和廣告推薦系統的即時需求,就連在Google這樣的公司也不重視。
但2010年張教授在Google贊助了李飛飛,使ImageNet資料庫成立,蒐集並提供了科學家120萬張影像去做研究。在短短2年間,AlexNet便利用ImageNet中的大量資料,以一個8層的卷積神經網路在ImageNet Challenge的影像辨識競賽中取得革命性的準確率,驚豔了學界與業界。此後業界開始投資大規模GPU運算平臺, 並接受了數據驅動的大規模機器學習之典範。
除卻電腦視覺的大躍進之外,另一個成就這波人工智慧革命的炸彈非AlphaGo莫屬。
 Photo Credit: Reuters / 達志影像
Photo Credit: Reuters / 達志影像在2016年時AlphaGo昭告了全世界如果一個算法能自行生產出無限多且多元的訓練數據,便能造就IQ 300的機器。但問題仍然是我們是否可以從小數據演繹出等同於無限多且多元的大數據?很可惜的,在除了下棋和電腦遊戲外,多數領域科學家還未找到這樣的方法。總地來說,這一波的人工智慧革命其實只推進了深度學習,而發展的面向也只限於模擬人腦的知覺(perception)中的視覺功能。至於如何使用人腦知覺之外的能力,譬如知識、記憶、計畫、邏輯思考等,都還有待未來發展。
- 本文內容出自《智慧新世界:圖靈所沒有預料到的人工智慧》
![[封面]智慧新世界](https://image1.thenewslens.com/2021/3/mpqkpnmlaat70v69hdj31wvx89ibgy.jpg?auto=compress&q=80&w=150) Photo Credit: 三民書局
Photo Credit: 三民書局本文經三民書局授權刊登
責任編輯:黃筱歡
核稿編輯:翁世航